

日本語の文章の解析は簡単?
日本語の文章の解析は簡単?
先日、日本語の文章で使われる単語の傾向を調べたいという話をいただきました。 英語の場合は、単語と単語の間に必ずスペースがあるので、簡単なプログラムで単語を抜き出すことができます。しかし、日本語の場合は単語と単語の切れ目は日本語の文法を考慮しないと難しくなります。
そこで、インターネットで検索したところ、単語の抽出をやってくれるパッケージがある事がわかりました。幾つか公開されているパッケージがある様でしたが、「MeCab」というバッケージがよく利用されている様なので、試してました。
この記事では、簡単に MeCab について調べたことをまとめてみました。
MeCab について
詳細は、インターネットを「MeCab」検索すれば出てくると思いますのでここでは詳しくは触れません。一応、MeCab の公式ページと言われるリンクを貼っておきます。
公式ページに行くと、Windows 版はインストレーションパッケージが配布されているので、ダウンロードしてインストールをすればすぐに利用できます。 Linux 版は、ソースコードが公開されているので、ダウンロードして自分でコンパイルをすれば使用できます。本体と日本語の解析に利用している辞書を作成してインストールします。
公式ページのインストラクションを見れば、Linux のコンパイルも殆ど問題なくできます。
MeCab の利用
MeCab を使用する場合、MeCab の処理した結果を利用する場合が多いと思います。実際は、MeCab の処理結果にさらに処理を加えて利用する事が多くなると思います。 こうした用途のために、外部のプログラムから MeCab を利用する仕組みも公開されています。今回は、この中から Python で MeCab を利用するための Wrapper「mecab-python3」を使ってみました。
(*)Python2.x 系の場合は、v1.0.2 を使うように、mecab-python3 の公式ページには書かれています。
Python 自体は、Python の公式ページからダウンロードできます。Windows/MacOS/Linux など多くのプラットフォームで利用できます。もちろん、このパッケージも利用できますが、ここでは機械学習のパッケージも予め組み込んでいる「Anaconda」を利用することをお勧めします。
開発やテストには、Python のコードを対話的に実行できる環境の方が便利です。Anaconda に含まれている、「jupyter notebook」は対話的な実行をサポートしています。
Anaconda の公式サイトへのリンクはこちらです。MeCab の処理結果を機械学習に利用したりする場合などは便利です。
無料のオープンソースパッケージを配布しているのでダウンロードして利用できます。Windows/Linux/MacOS で利用可能です。
MeCab の導入
Windows の場合は、インストールパッケージをダウンロードして実行します。 Linux の場合は、ソースコードをダウンロードして MeCab のビルドを行う必要があります。 詳細は、公式ページのインストールを参照してください。
Ubuntu の場合は、「make」と「g++(GNU c++コンパイラ)」が必要になります。あらかじめ以下のコマンドを実行してインストールしておく必要があります。
(*) 記事を読まれた方から指摘があり、ビルドはしなくても、pipでMeCab本体と、辞書のインストールをすることも可能です。参考リンク
自分でビルドする場合は以下のパッケージが必要です。
$ sudo apt update
$ sudo apt install make
$ sudo apt install g++
MeCab の本体と辞書を構築してインストールします。
MeCab の Python ラッパーのインストール
最初に、MeCab を Python のプログラムから呼び出すためのラッパー(Wrapper)をインストールします。インストールには Python のパッケージに含まれているパッケージ管理のモジュール「pip」を使います。 実行は、コマンドラインから以下のコマンドを実行します。
$ pip install mecab-python3
もしくは
$ python -m pip install mecab-python3
を実行します。Mac や Ubuntu などでは、Python をシステムにインストールしている場合は、「sudo」をつけて実行する必要があります。もしくは、スーパーユーザー(root)で実行します。
殆どの場合問題なくインストールできると思いますが、Python のパス(path)設定がされていない場合や、複数のバージョンの Python がインストールされている場合は上手くいかない場合があります。このラッパーは実際にプログラムで使用するバージョンの Python に追加する必要があります。
Python からの使い方
Anaconda の中の、「jupyter notebook」を利用します。Python で MeCab を利用する基本のコードは以下のようなコードです。
import MeCab
source = "テストの文章を入れます"
option = "-d /usr/local/lib/mecab/dic/mecab-ipdic-neologd"
tagger = MeCab.Tagger(option)
result = tagger.parse(source)
print(result)
「option」に MeCab のコマンドラインのオプションを指定できます。上の例では、MeCab が使用する辞書に「mecab-ipdic-neologd」を指定しています。必要に応じて出力の形式も指定できるので便利です。
jupyter notebook を使って実行する場合は、最初に jupyter notebook を起動します。 Windows の場合は、スタートメニュから選択して起動するのが一般的ですが、Linux などでは、コマンドラインから
$ jupyter notebook
と入力すると、Web ブラウザが立ち上がって、UI を使える様になります。 あとは、「In」というブロックにコードを書いていくと、ブロック内のコードのみを実行して結果を表示することができるので、「対話的実行」に向いています。もちろん、テキストファイルから入力文章を取り込む事も可能です。
このようにすることで、MeCab の出力結果を見ながらプログラムを書く事ができるために開発効率を上げる事ができます。将来的には、MeCab の出力を機械学習(Machne Learning)で処理することも想定しているので、Anaconda を選択しました。Anaconda を使うと、機械学習の実験も対話的にできるため便利です。
以下が「jupoyter notebook」を利用した例です。上のサンプルとは出力のプリントをする部分が追加されていますが基本的に同じコードです。
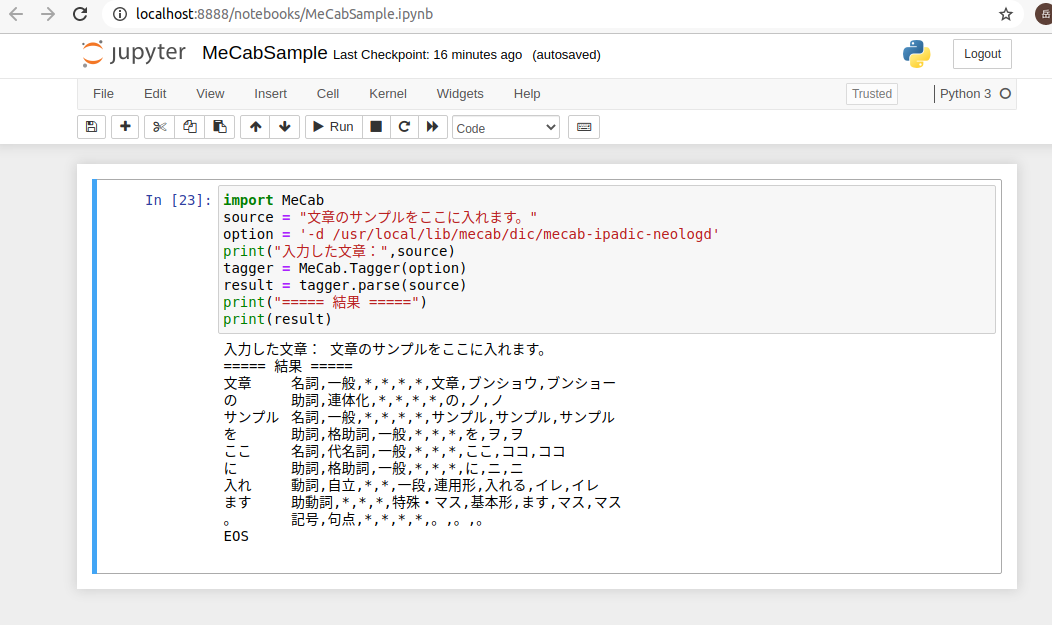
基本的な Python からの利用方法は以上です。
まとめ
日本語の文章から単語を抜き出す処理を、MeCab という形態素解析エンジンを利用して Python で利用する方法を紹介しました。MeCab を使うと、難しそうに思える、単語を日本語の文章から抜き出す処理を MeCab が行ってくれるため、その結果を利用したアプリケーションの開発が簡単にできます。
今回は、MeCab を Python から利用するための設定を中心にお届けしました。Python は機械学習のパッケージも充実しているため、MeCab の結果を利用したアプリケーションと機械学習を組み合わせた開発も可能です。こうしたことを想定して、Python の実行環境として、機械学習のパッケージもあらかじめ組み込まれている、Anaconda を使う方法を選んでみました。
次回からは実際の利用の例などを紹介する予定です。お楽しみに!